[1일차] 처음 만나는 자연어처리
[ 1일차(처음 만나는 자연어처리) 목록 ]
1-1. 딥러닝 기반 자연어 처리 모델
1-2. 트랜스퍼 러닝
1-3. 학습 파이프라인
1-4. 개발 환경 설정
==========
1-1. 딥러닝 기반 자연어 처리 모델(p.12 ~ 16)
1) 이론
# 기계의 자연어 처리: 입력 > 모델(함수) > 출력(확률)
- 예시:
[ 입력(자연어) > 출력(확률) > 후처리 ]
재미없는 편인 영화에요 > [0.0, 0.3, 0.7]: 긍정, 중립, 부정 > 부정(negative)
- 딥러닝도 모델! (Hidden layer를 사용하는 모델)
- 모델을 만드려면 데이터가 필요하며, 이 데이터는 라벨링(labeling)으로 확보 => training (labeling된 데이터의 패턴을 모델이 익히게 함)
- 자연어 처리 관련해 BERT(Bidirectional Encoder Representations from Transformer), GPT(Generative Pre-trained Transformer)가 주목
1-2. 트랜스퍼 러닝
1) 이론
# 트랜스퍼러닝(Transfer learning): 특정 task를 작업한 학습모델을 다른 task에 재사용하는 기법 (knowledge transfer)
- 모델 학습 속도가 빨라지고 + 새로운 테스크(downstream task)를 더 잘 맞춤.
- 재사용한 모델에 데이터만 새로 추가
데이터1 > “모델” > 테스크1(upstream task) ==> 프리트레인(pretrain)
데이터2 > “모델” > 테스크2(downstream task)
- Pretrain에서 자연어의 풍부한 문맥(context)을 모델에 내재화 하고 downstream task에서 활용해 성능을 끌어올림.
=> 언어 모델(Language Model)
=> GPT의 pretrain 중 하나는 “단어 맞추기”
=> BERT의 pretrain 중 하나는 “빈칸 채우기“ => 마스크 언어 모델(Masked Language Model)
- Pretrain에서 사람의 수작업 없이 다량의 학습데이터 내에서 정답을 만들고 + 모델을 학습하는 방법
=> 자기지도학습(self-supervised learning)
(아래는 자기지도학습과 준지도학습, 비지도학습의 차이를 비교한 것. 출처: Bard) => label이 지정되었는 지 유무에 따라 준지도학습과 구분됨.


# 파인 튜닝(Fine-tuning)
- 자연어처리의 궁극적 목표는 downstream task (예: classification)
=> Downstream task는 파인 튜닝(Fine-tuning)을 통해 학습
=> Fine-tuning: Pretrain을 마친 모델을 downstream task에 맞게 UPDATE !
- 문서 분류: 문서나 문장을 입력받아 어떤 범주에 속하는 지 확률값 반환
.여기서 각각 문장의 시작과 끝에 CLS, SEP라는 특수한 토큰(token)을 붙는데, 토큰 및 토큰화(tokenizeation)에 대한 이해가 필요.
- 자연어 추론: 문장 2개를 입력받아 두 문장 사이 관계가 참(entailment) or 거짓(contradiction) or 중립(neutral) 인지 확률값 반환
- 개체명 인식: 문서나 문장을 입력받아 단어 별로 기관명, 인명, 지명 등 어떤 개체의 범주에 속하는 지 확률값 반환
- 질의 응답: 질문과 지문을 입력받아 각 단어가 정답의 시작일 확률값과 끝일 확률값을 반환
- 문장 생성: 문장을 입력받아 어휘 전체에 대한 확률값 반환
# 파인튜닝 외 학습방법
1) 프롬프트 튜닝(prompt tuning): 다운태스크 데이터 전체 사용. 모델 일부 업데이트.
2) 인컨텍스트 러닝(in-context learning): 다운태스크 데이터 일부만 사용. 모델 업데이트 하지 않음.
3) 제로샷 러닝(zero-shot learning): 다운태스크 데이터 사용 안함. 모델이 바로 다운태스크 수행.
4) 원샷 러닝(one-shot learning): 다운태스크 데이터 1개만 사용. 이후 모델이 다운태스크에 수행 될지 여부 결정.
5) 퓨샷 러닝(few-shot learning) : 다운태스크 데이터 몇 개만 사용. 이후 모델이 다운태스크에 수행 될지 여부 결정.
1-3. 학습 파이프라인
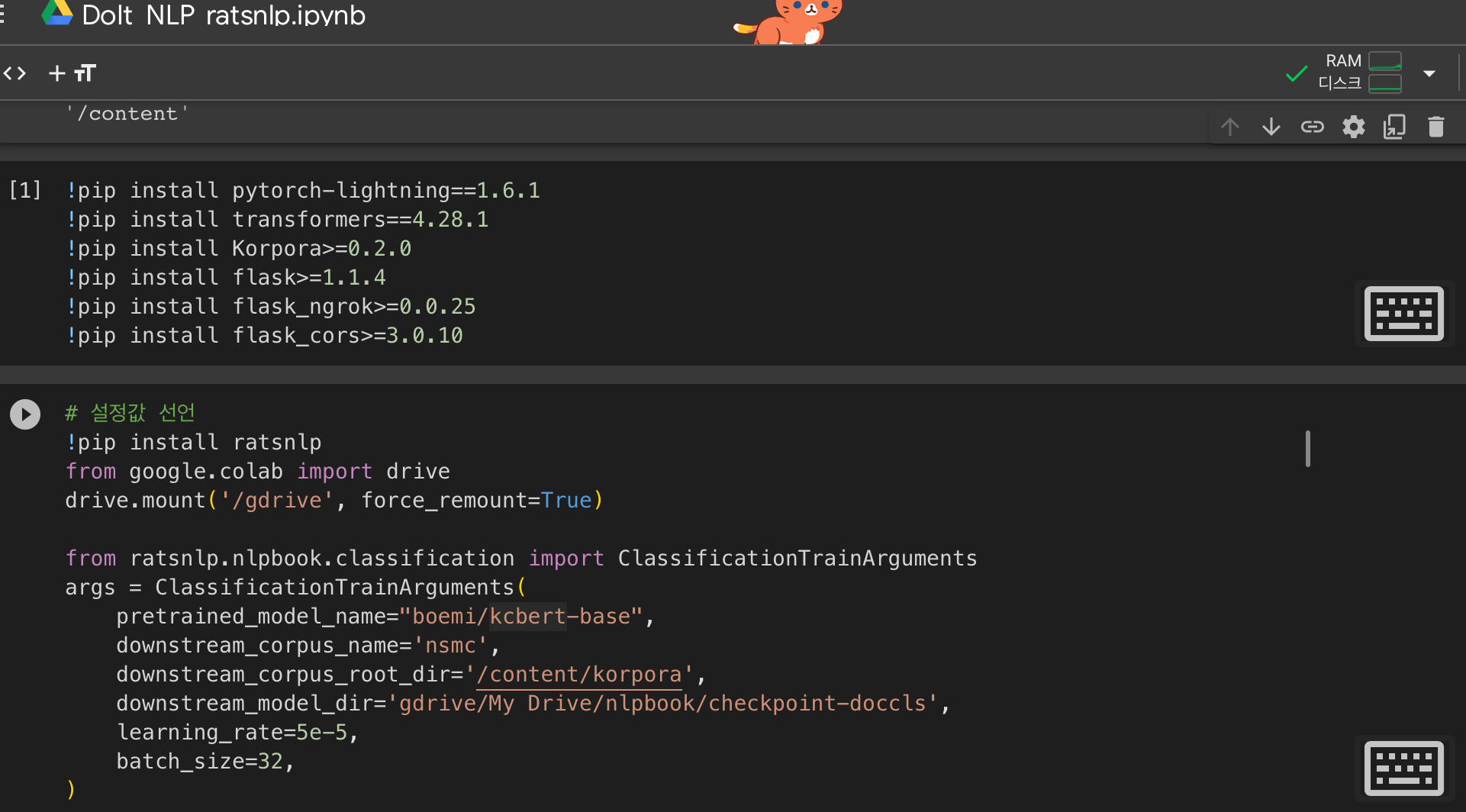
1) 오픈소스 파이썬 패키지(ratsnlp: github.cm/ratsgo/tartsnlp)
- 설정값: Pretrain model, Dataset, 저장소, Hyper-parameter
2) 설정값 선언
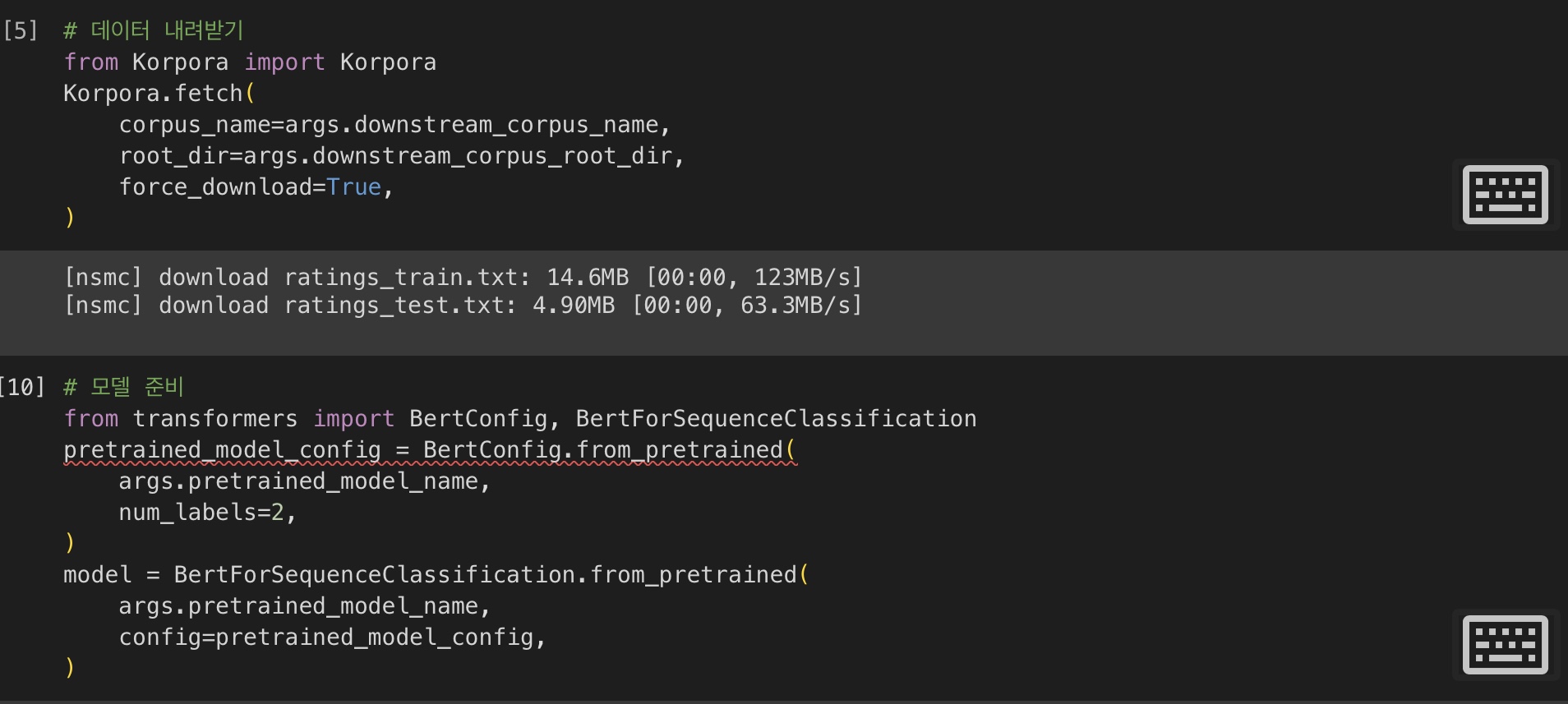
3) 데이터 다운로드
4) 모델 준비 => 이 단계에서 kcbert-base 모델이 hugging face로부터 내려받아지지 않아 오류가 발생했습니다(추후 다시 시도 예정).
5) 토크나이저 준비
6) 데이터 로더 준비
7) 태스크 정의
8) 모델 학습