-
[혼공머신] 3주차 과제 - 다양한 분류 알고리즘AI/혼공학습단9기_DL&ML 2023. 1. 19. 09:23
1. Contents
- Logistic Regression(로지스틱 회귀): 선형 방정식을 사용한 분류 알고리즘. 선형 회귀와 달리 Sigmoid 나 Softmax function을 사용하여 클래스 확률을 출력할 수 있음.
- Solver 매개변수에서 사용할 알고리즘을 선택할 수 있음
- Sover 매개변수의 기본값은 'lbfgs'임.
- 'sag'는 확률적 평균 하강법 알고리즘으로서, 특성과 샘플수가 많을 때 성능이 좋고 빠른 매개변수임. Overfitting(과대적합)이 되었을 경우 'sag'알고리즘으로 변경 고려.
- 'penalty'매개변수에서 L2규제(릿지)와 L1규제(라쏘)를 선택할 수 있음(기본값: l2 (L2규제))
- 'C' 매개변수에서 규제 강도를 제어하며 기본값은 1.0임(숫자가 작을 수록 규제 강함).
- Stochastic Gradient Descent(SGD: 확률론적 경사 하강법): 훈련 세타에서 샘플을 하나씩 꺼내 손실함수의 경사를 따라 최적의 모델을 찾는 알고리즘. 샘플을 하나씩 사용하지 않고 여러 개 사용하면 미니배치 경사 하강법, 전체 샘플을 사용하면 배치 경사 하강법임.
- SGDClassifier(확률적 경사 하강 분류 모델)
- Loss 매개변수는 확률적 경사 하강법으로 최적화할 손실 함수를 지정함. 기본값은 서포트 백신 머신을 위한 'hinge' 손실함수임. 로지스틱 휘기를 위해서는 'log'로 지정함. 'penalty' 매개 변수에서 규제 종류, 'alpha' 매개변수에서 규제 강도를 지정함.
- max_iter. 매개변수는 에포크 횟루를 지정함(기본값: 1000).
- tol 매개변수는 반복을 멈출 조건으로 기본값은 0.001.
- n_iter_no_change 매개변수는 지정한 에포크 동안 손실이 tol만큼 줄어들지 않으면 알고리즘이 중단되게 하며 기본값은 5임.
- SGDRegressor(확률적 경사 하강 회귀 모델): 확률적 경사 하강법을 사용한 회귀 모델로, loss 매개변수에서 손실 함수를 지정함. 기본값은 제곱오차를 나타내는 'squared_loss'임. 대부분의 매개변수는 SGDClassifier에서 동일하게 사용됨.
- Multi-Classification(다중 분류): 타겟 클래스가 2개 이상인 분류 문제. 로지스틱 회귀는 다중 분류에 의해 Softmax function을 사용하여 클래스를 예측함.
- Loss Fucntion(손실 함수): 샘플 하나에 대한 손실을 정의함. Cost function(비용 함수)는 훈련 세트에 있는 모든 샘플에 대한 손실함수의 합. 보통 둘을 엄격히 구분하지 않고 쓰기도 함. 확률적 경사 하강법을 사용할 경우 최적화 할 대상이 이 손실함수임. 대부분의 문제에 잘 맞는 손실함수는 이미 정의되어 있는데, 이진 분류에는 로지스틱 회귀(또는 이진 크로스 엔트로피) 손실 함수를 사용하고, 다중 분류에는 크로스엔트로피 손실함수를 사용함. 회귀 문제에는 평균 제곱 오차 손실 함수를 사용함.
- Epoch(에포크): 확률적 경사 하강법에서 전체 샘플을 모두 사용하는 한번 반복을 의미함. 일반적으로 경사 하강법 알고리즘은 수십에서 수백 번 에포크를 반복함.
- Sigmoid Function(시그모이드 함수): 선형 방정식의 출력을 0과 1 사이의 값으로 압축하며 이진 분류를 위해 사용함.
- Softmax Function(소프트맥스 함수): 다중 분류에서 여러 선형 방정식의 출력 결과를 정규화하여 합이 1이 되도록 만듬.
- predict_proba(): 예측 확률을 반환
- 이진 분류는 샘플마다 음성 클래스와 양성 클래스에 대한 확률 반환
- 다중 분류는 샘플마다 모든 클래스에 대한 확률 반환
- decision_function(): 모델이 학습한 선형 방정식의 출력을 반환
- 이진 분류의 경우 양성 클래스의 확률이 반환(0보다 크면 양성 클래스, 작거나 같으면 음성 클래스로 예측)
- 다중 분류의 경우 각 클래스마다 선형 방정식 계산(가장 큰 값의 클래스가 예측 클래스)
2. 기본 미션
- 로지스틱 회귀가 이진 분류에서 확률을 출력하기 위해 사용하는 함수?
: 이진 분류를 위해서는 시그모이드 함수를 사용하며, 선형방정식 결과를 0 또는 1로 해석합니다.
아래는 decision 배열을 softmax()함수에 전달한 예입니다. softmax()의 axis 매개변수는 계산한 축으로서, axis=1로 지정하여 각 행(샘플)에 대해서 softmax를 계산합니다. 만약 axis를 지정하지 않으면 전체 배열에 대해서 소프트맥스를 계산합니다.

Softmax Test 3. 선택 미션
- 과대적합 / 과소적합 손코딩
1) 과대적합/과소적합을 시험하기 앞서, 물고기 정보를 담고 있는 데이터를 준비(data preparation) 합니다. CSV파일로 부터 불러드려온 pandas data는 numpy array로 변경한 후 변수에 저장합니다.
Data Preparation sklean.model_selection 라이브러리를 통해 train과 testset image를 분리하고 StandardScaler()를 통해 데이터를 정형화 시킵니다. 여기서 train data는 fit과 transform을 통해(fit_trainsform()), test data는 transform()만을 통해 scale을 맞춥니다.
SGDClassifier(확률적 경사 하강 분류모델)을 통해 train data를 학습(fit)시키고 score를 통해 정확도를 확인합니다. 이때 train data 뿐아니라 test data의 score를 같이 비교함으로써 over/under fitting을 확인합니다.

Training Score를 그래프로 확인함으로써 epoch에 따른 학습 정확도를 확인할 수 있습니다. 이것은 over/under fitting을 확인하는 데에도 도움이 됩니다.
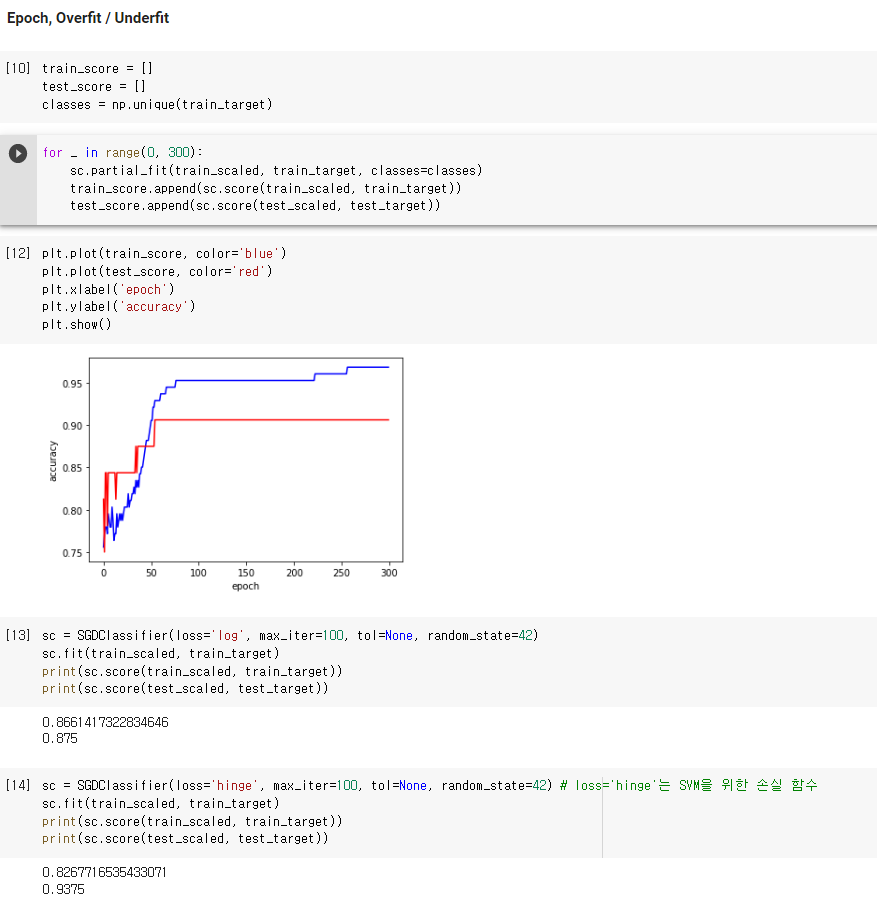
Over/Underfitting Check SGDClassifier를 통해 학습한 결과(trainset과 testset의 score)를 확인합니다.
'AI > 혼공학습단9기_DL&ML' 카테고리의 다른 글
[혼공머신] 5주차 과제 - 비지도 학습 (0) 2023.02.01 [혼공머신] 4주차 과제 - 트리 알고리즘 (0) 2023.01.26 [혼공머신] 2주차 과제 - 회귀모델 (0) 2023.01.12 [혼공머신] 1주차 과제 - 데이터 전처리, 훈련/시험세트 (0) 2023.01.08 혼공학습단으로 시작하는 딥러닝 공부 !! (0) 2023.01.08 - Logistic Regression(로지스틱 회귀): 선형 방정식을 사용한 분류 알고리즘. 선형 회귀와 달리 Sigmoid 나 Softmax function을 사용하여 클래스 확률을 출력할 수 있음.